Содержание:
- Как удалить дублирующиеся строки из таблицы SQL Server?
- Удаление дублирующихся строк из таблицы SQL Server с уникальным индексом
- Метод 1: Выборка дубликатов записей с помощью функции «ROW_NUMBER ()»
- Метод 2: Выборка дубликатов записей с помощью функции «NOT IN ()»
- Метод 1: Удаление дублирующихся записей с помощью функции «ROW_NUMBER ()»
- Метод 2: Удаление дублирующихся записей с помощью функции «NOT IN ()»
- План выполнения и стоимость запроса для удаления дубликатов строк из индексированной таблицы:
- Удаление дубликатов из таблицы SQL Server без уникального индекса:
- Метод 1: Удаление дубликатов строк из таблицы с помощью функции «ROW_NUMBER ()» и JOINS.
- Метод 2: Удаление дубликатов строк из таблицы с помощью функции «ROW_NUMBER ()» и PARTITION BY.
При проектировании объектов в SQL Server мы должны следовать определенным лучшим практикам. Например, таблица должна иметь первичные ключи, столбцы идентификации, кластеризованные и некластеризованные индексы, ограничения целостности данных и производительности. Таблица SQL Server не должна содержать дублирующихся строк в соответствии с лучшими практиками проектирования баз данных. Иногда, однако, нам приходится иметь дело с базами данных, где эти правила не соблюдаются или где возможны исключения, когда эти правила намеренно обходятся. Несмотря на то, что мы следуем лучшим практикам, мы можем столкнуться с такими проблемами, как дублирование строк.
Например, мы также можем получить этот тип данных при импорте промежуточных таблиц, и мы хотели бы удалить избыточные строки перед тем, как добавить их в производственные таблицы. Кроме того, мы не должны оставлять перспективу для дублирования строк, поскольку дублирующаяся информация позволяет многократно обрабатывать запросы, получать некорректные результаты отчетности и многое другое. Однако если у нас уже есть дублирующиеся строки в столбце, нам нужно следовать определенным методам, чтобы очистить дублирующиеся данные. Давайте’ рассмотрим в этой статье некоторые способы удаления дублирования данных.
Как удалить дублирующиеся строки из таблицы SQL Server?
В SQL Server существует несколько способов обработки дубликатов записей в таблице в зависимости от конкретных обстоятельств, например:
Удаление дублирующихся строк из таблицы SQL Server с уникальным индексом
Вы можете использовать индекс для классификации дублирующихся данных в уникальных индексных таблицах, а затем удалить дублирующиеся записи. Во-первых, нам необходимо создайте базу данных с именем «test_database», затем создайте таблицу «Сотрудник» с уникальным индексом, используя приведенный ниже код.
USE master GO CREATE DATABASE test_database GO USE [test_database] GO CREATE TABLE Employee ( [ID] INT NOT NULL IDENTITY(1,1), [Dep_ID] INT, [Name] varchar(200), [email] varchar (250) NULL, [город] varchar(250) NULL, [адрес] varchar(500) NULL CONSTRAINT Primary_Key_ID PRIMARY KEY(ID) )
Вывод будет выглядеть следующим образом.

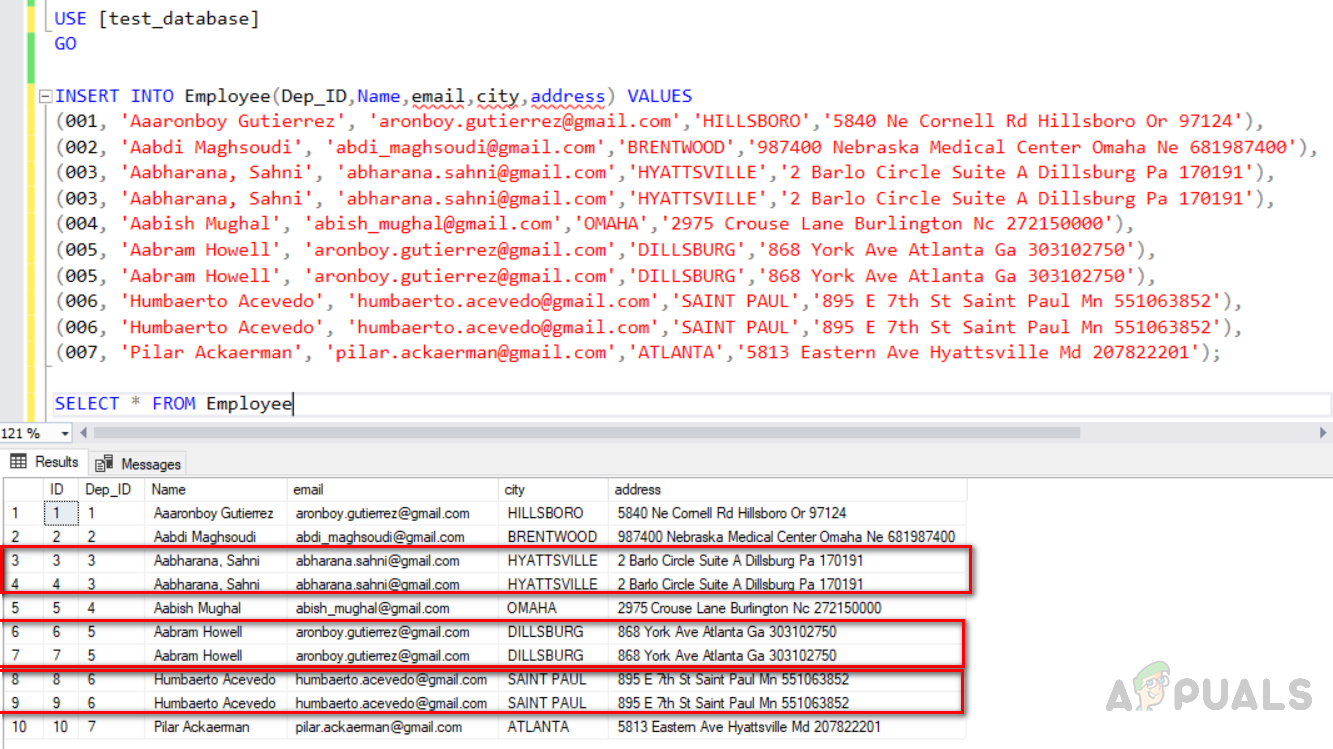
Теперь вставьте данные в таблицу. Мы также вставим дублирующиеся строки. «Dep_ID» 003, 005 и 006 — это дубликаты строк с одинаковыми данными во всех полях, кроме столбца identity с уникальным ключевым индексом. Выполните приведенный ниже код.
USE [test_database] GO INSERT INTO Employee(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201'); SELECT * FROM Employee
Выходные данные будут выглядеть следующим образом.

Теперь найдите количество строк в таблице, выполнив следующий код. Функция count(*) подсчитает количество строк.
SELECT Dep_ID, Name, email, city, address, COUNT(*) AS duplicate_rows_count FROM Employee GROUP BY Dep_ID,Name,email,city,address
Результат будет выглядеть следующим образом. Строки № (3, 4), (6, 7), (8, 9), выделенные красной рамкой, являются дублирующими.
Наша задача — обеспечить уникальность путем удаления дубликатов для дублирующихся столбцов. Удалить дублирующиеся значения из таблицы с уникальным индексом немного проще, чем удалить строки из таблицы без него. Ниже приведены два метода для достижения этой цели. Первый метод дает вам дубликаты строк из таблицы с помощью функции «row_number()», в то время как второй метод использует функцию «NOT IN». Эти два метода имеют свою стоимость, которая будет рассмотрена позже.
Метод 1: Выборка дубликатов записей с помощью функции «ROW_NUMBER ()»
выберите * из (SELECT Dep_ID, имя, email, город, адрес, ROW_NUMBER() OVER ( РАЗДЕЛЕНИЕ ПО Dep_ID, Name, email, city, address ORDER BY Dep_ID, имя, электронная почта, город, адрес ) row_no FROM test_database.dbo.Employee) x где row_no>1
Метод 2: Выборка дубликатов записей с помощью функции «NOT IN ()»
SELECT * FROM test_database.dbo.Сотрудник WHERE ID NOT IN (SELECT MAX(ID)) FROM база данных test_database.dbo.Сотрудник GROUP BY Dep_ID,Name,email,city,address)
Выполните приведенный выше код и вы увидите следующий результат. Оба метода дают одинаковый результат, но имеют разную стоимость.

Теперь мы удалим выбранные выше дубликаты строк с помощью «CTE», используя следующий код. Следующий код выбирает дубликаты строк для удаления с помощью функции «ROW_NUMBER ()».
Метод 1: Удаление дублирующихся записей с помощью функции «ROW_NUMBER ()»
WITH cte_delete AS ( SELECT Dep_ID, имя, электронная почта, город, адрес, ROW_NUMBER() OVER ( РАЗДЕЛЕНИЕ ПО Dep_ID, Name, email, city, address ORDER BY Dep_ID, Name, email, city, address ) row_no FROM тестовая база данных.dbo.Сотрудник ) DELETE FROM cte_delete WHERE row_no > 1;
Результат будет выглядеть следующим образом.

Метод 2: Удаление дублирующихся записей с помощью функции «NOT IN ()»
Теперь, чтобы проверить другой метод, нам нужно усечь таблицу, что приведет к удалению всех строк из таблицы. Затем команда insert добавит значения в таблицу. Теперь выполните следующий код.
USE [test_database] GO усечение таблицы test_database.dbo.Сотрудник INSERT INTO Employee(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201'); SELECT * FROM Employee
Вывод будет выглядеть следующим образом.
Выполните приведенный ниже код, чтобы удалить все дублирующиеся строки из таблицы «Employee».
Delete FROM test_database.dbo.Сотрудник WHERE ID NOT IN (SELECT MAX(ID)) FROM база данных test_database.dbo.Сотрудник GROUP BY Dep_ID,Name,email,city,address)
Выходные данные будут выглядеть следующим образом.

План выполнения и стоимость запроса для удаления дубликатов строк из индексированной таблицы:
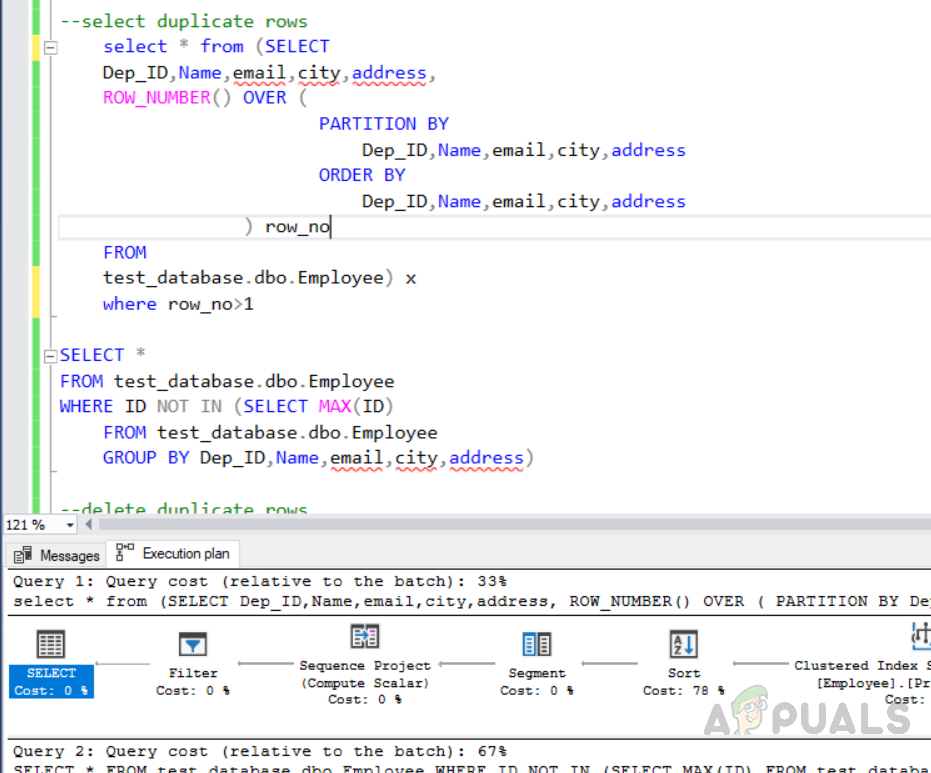
Теперь нам нужно проверить, какой метод будет экономически эффективным и займет меньше ресурсов. Выберите код и нажмите на план выполнения. Появится следующий экран, показывающий все выполняющиеся планы вместе с процентом затрат.
Мы видим, что метод 1 «удаление дубликатов записей с помощью функции «ROW_NUMBER ()»» имеет стоимость 33%, а метод 2 «удаление дубликатов записей с помощью функции NOT IN ()» имеет стоимость 67%. Таким образом, первый метод является наиболее экономически эффективным по сравнению со вторым методом.
Удаление дубликатов из таблицы SQL Server без уникального индекса:
Немного сложнее удалить дублирующиеся строки или таблицы без уникального индекса. В этом сценарии использование общего табличного выражения (CTE) и функции ROW NUMBER() помогает нам удалить дубликаты записей. Для удаления дубликатов из таблицы без уникального индекса нам нужно сгенерировать уникальные идентификаторы строк.
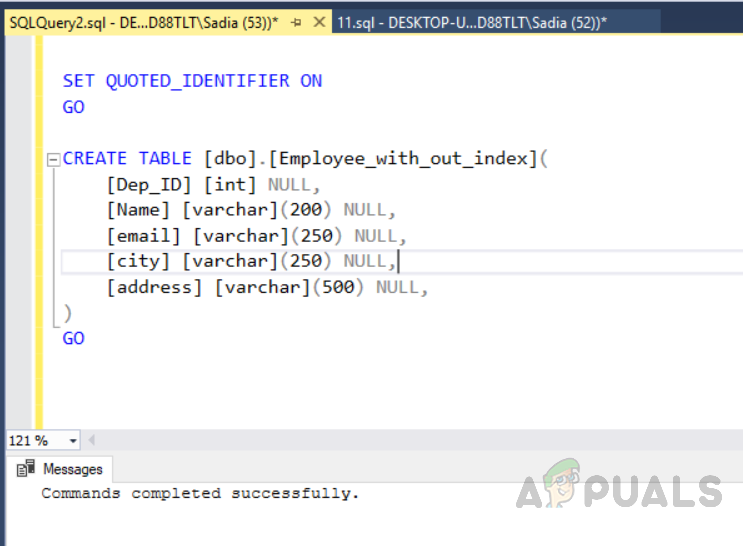
Выполните следующий код, чтобы создать таблицу без уникального индекса.
USE [test_database] GO SET ANSI_NULLS ON GO УСТАНОВИТЕ QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Employee_with_out_index]( [Dep_ID] [int] NULL, [Имя] [varchar](200) NULL, [email] [varchar](250) NULL, [город] [varchar](250) NULL, [адрес] [varchar](500) NULL, ) GO
Выходные данные будут выглядеть следующим образом.
Теперь вставьте записи в созданную таблицу с именем «Employee_with_out_index», выполнив следующий код.
USE [test_database] GO INSERT INTO Employee_with_out_index(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto').acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201'); SELECT * FROM Employee_with_out_index
Выходные данные будут выглядеть следующим образом.

Метод 1: Удаление дубликатов строк из таблицы с помощью функции «ROW_NUMBER ()» и JOINS.
Выполните следующий код, который использует функцию ROW_NUMBER () и JOIN для удаления дубликатов строк из таблицы без индекса. IT сначала создает уникальный идентификатор для присвоения row_no всем строкам и сохраняет только одну строку, удаляя дубликаты.
WITH temp_tablr_with_row_ids AS ( SELECT ROW_NUMBER() OVER (ORDER BY Dep_ID,Name,email,city,address) AS row_no, Dep_ID, имя, email, город, адрес FROM база данных test_database.dbo.Employee_with_out_index ) DELETE a FROM temp_tablr_with_row_ids a WHERE row_no < (SELECT MAX(row_no) FROM temp_tablr_with_row_ids i WHERE a.Dep_ID=i.Dep_ID и a.имя=i.Имя и a.email=i.электронная почта и.город=i.город и а.адрес=i.адрес GROUP BY Dep_ID,Name,email,city,address)
Выходные данные будут выглядеть следующим образом.

Метод 2: Удаление дубликатов строк из таблицы с помощью функции «ROW_NUMBER ()» и PARTITION BY.
В этом методе мы используем функцию ROW_NUMBER вместе с предложением partition by, чтобы присвоить row_no всем строкам, а затем удалить дубликаты. Прежде всего, нам нужно усечь ту же таблицу, которую мы создали ранее, чтобы все данные были удалены из таблицы. Затем вставьте записи в таблицу, включая дубликаты записей. Третий запрос удалит дублирующиеся строки из таблицы с именем «Employee_with_out_index».
усечь таблицу Employee_with_out_index INSERT INTO Employee_with_out_index(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201');
Выборка дубликатов записей в временную таблицу
; WITH temp_tablr_with_row_ids AS ( SELECT ROW_NUMBER() OVER (PARTITION BY Dep_ID,Name,email,city,address ORDER BY Dep_ID,Name,email,city,address) AS row_no, Dep_ID,Name,email,city,address FROM Сотрудник_без_индекса )
Удаление дубликатов записей из временной таблицы
DELETE a FROM temp_tablr_with_row_ids a WHERE row_no > 1
Выходные данные будут выглядеть следующим образом.

Кроме того, нам необходимо знать о стоимости выполнения запроса, чтобы понять, какое из решений является оптимизированным. Поэтому нужно выбрать все соответствующие запросы и нажать на план выполнения. На изображении ниже показан план выполнения запросов вместе со стоимостью выполнения. Запросы на удаление выделены в красном поле. Первый запрос, который использует «ROW_NUMBER ()» и JOIN clause, имеет 56% стоимости выполнения, в то время как второй запрос, использующий «ROW_NUMBER ()» и «PARTITION BY» имеет 31% стоимости выполнения. Таким образом, второй метод является более оптимизированным, и мы должны следовать оптимизированному решению.

Еще по теме:
 Как перечислить все базы данных и таблицы с помощью PSQL?
Как перечислить все базы данных и таблицы с помощью PSQL?
 Как использовать DROP IF EXISTS в SQL Server?
Как использовать DROP IF EXISTS в SQL Server?
 Как настроить почту базы данных в SQL Server с помощью Gmail?
Как настроить почту базы данных в SQL Server с помощью Gmail?
 Как разделить строку по разделительному символу в SQL Server?
Как разделить строку по разделительному символу в SQL Server?
 Как исправить ошибку ‘A Network-related or Instance-specific Error occurred while Establishing a Connection to SQL Server’ ?
Как исправить ошибку ‘A Network-related or Instance-specific Error occurred while Establishing a Connection to SQL Server’ ?
 Как переименовать базу данных SQL Server?
Как переименовать базу данных SQL Server?